Overall Survey
credit to : Efficient Large Language Models: A Survey
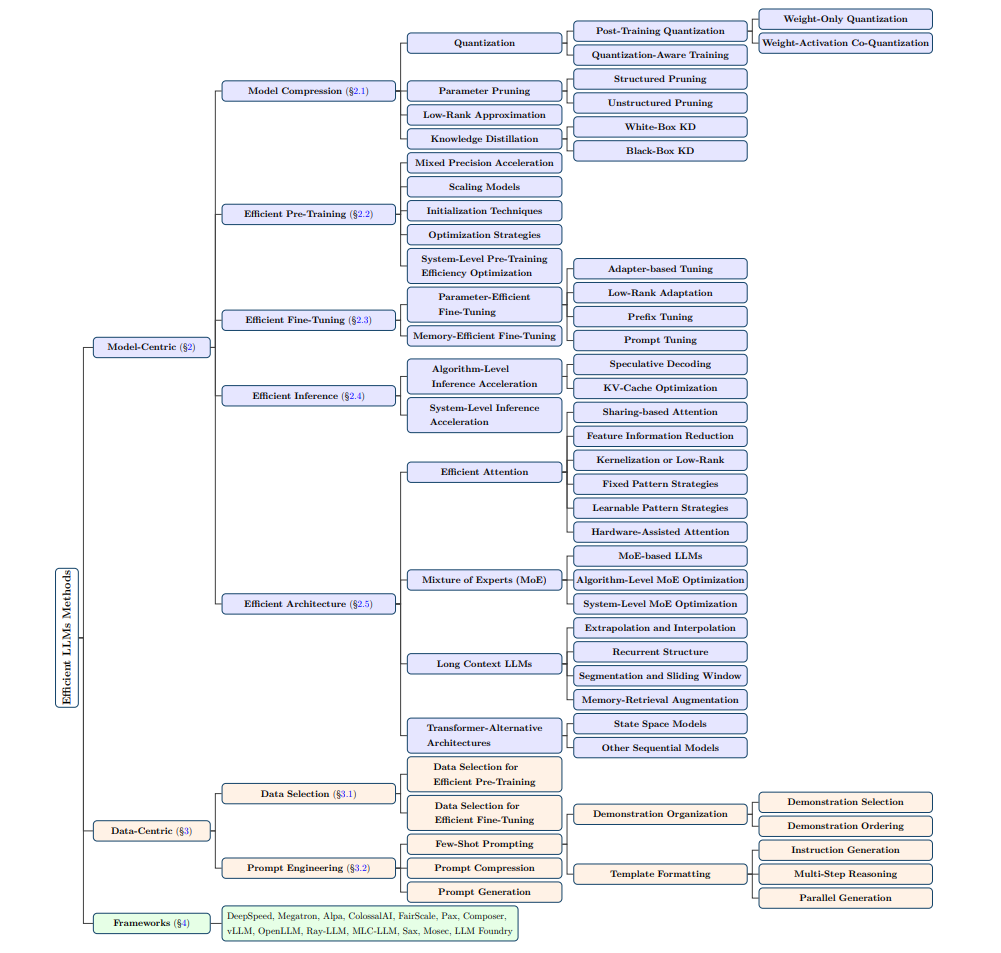
这篇综述将加速方法分成三类,如图所示。
Model-Centric Methods
Model Compression
Quantization
- 将数据从高精度 \(X^H\) 转化为 低精度\(X^L\):
$XL=round(XH) $
- PTQ(post-training quantization)
- 分为 Weight-Only Quantization 和 Weight-Activation Co-Quantization
- Weight-Only Quantization:将权重量化至 8bit,4bit,3bit等等,同时一些研究发现需要单独处理一些量化误差较大的权重,所以通常用一些算法对部分权重进行量化,而部分权重保留较高精度。
- Weight-Activation Co-Quantization:由于 activation outliers 的存在,这种量化会更加困难复杂,容易损失更多的精度,因此分组量化、精度补偿等算法更加重要
- QAT(Quantization-Aware Training)
- 量化后重新训练,能减小量化精度,但会花费更大的成本
各种具体量化方法后文再介绍,这里仅作提要
Parameter Pruning
- 丢弃不必要的权重
- Structured Pruning
- 剪掉一整行,一整列,一整层,等等,需要根据权重、梯度等信息
- Unstructured Pruning
- 通常与稀疏化感知一起进行,对权重单独剪枝
Low-Rank Approximation \(W\approx UV^T, W\in R^{m\times n}, U\in R^{m\times r}, V\in R^{n\times r}\)
Knowledge Distillation
- KD 通过训练较小的学生模型来模拟 LLM 作为教师模型的性能来压缩 LLM,从而使学生模型的计算量较小,但仍保持与教师模型类似的高水平性能。
- TODO

Efficient Pre-Training
Mixed Precision Acceleration
- 使用低精度模型进行前向和后向传播,将计算出的低精度梯度转换为高精度梯度来更新原始高精度权重,从而提高预训练效率
- 提高内存效率
- 具体各种算法后文再介绍
Scaling Models
Initialization Techniques
Optimization Strategies
- 对优化器算法进行改进,以减少内存需求,后文再进行介绍
System-Level Pre-Training Efficiency Optimization
- 聚焦于分布式训练,以应对内存需求,具体有张量并行,数据并行等,还涉及节点间通信,非常复杂,以后再单独细讲

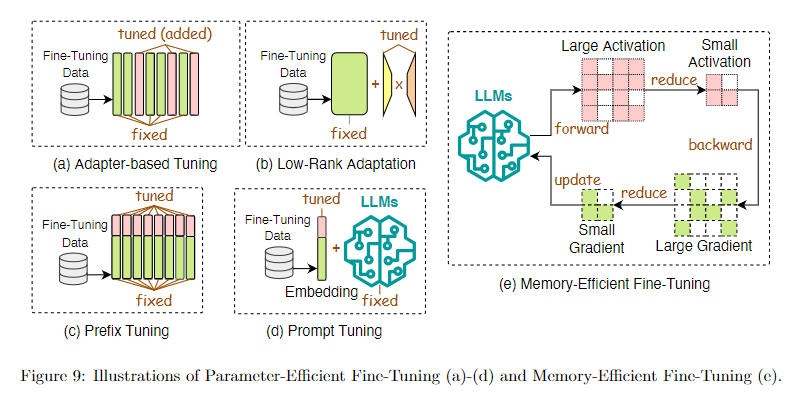
Efficient Fine-Tuning
- Parameter-Efficient Fine-Tuning(PEFT)
- Adapter-based Tuning
- Low-Rank Adaptation
- Prefix Tuning
- Prompt Tuning
- Memory-Efficient Fine-Tuning(MEFT)
- 结合量化感知等算法进行微调,以减少内存需求,经典的有 QLora,QA-Lora 等
微调算法原理基本如图,不同具体算法的原理与优缺点后文再介绍
Efficient Inference
Data-Centric Methods
TODO