关于
本篇 blog 简要介绍 stable diffusion 相关知识以及在加速器上的 finetune deploy 实验。
基本原理
github: Stable Diffusion v1
论文地址:Rombach_High-Resolution_Image_Synthesis_With_Latent_Diffusion_Models
非常好解读:reference
- 核心:将图片通过一个单独训练的 autoencoder 压缩到潜空间中,再进行 diffusion model 的训练,能够大大降低计算量(相较于高分辨率对 pixel 直接进行训练),同时,autoencoder还能用于多种任务中,即该方法对 image-to-image 和 text-to-image 都有效
Autoencoder
- Encoder: $z=(x), x R^{HW} $
- Decoder: \(\tilde{x} = D(z) = D(\varepsilon(x)), z\in R^{h\times w \times c}\)
- textencoder:使用的是 CLIP model
- 训练方法:
Diffusion Model
- Diffision model can be interpreted as an equally weighted sequence of denoising autoencoders: \(\epsilon_\theta(x_t, t); t=1, 2, \dots, T\),即预测噪声的网络,其中,\(x_t\) is a noisy version of the input \(x\)
- 目标损失函数为:\(L_{DM}= E_{x, \epsilon \sim N(0, 1), t \sim uniform(1, 2, ... T)}[||\epsilon - \epsilon_\theta(x_t, t)||_2^2]\)
- LDM中,目标损失函数为:\(L_{LDM}:= E_{\varepsilon(x), \epsilon \sim N(0, 1), t}[||\epsilon - \epsilon_\theta(z_t, t)||_2^2]\)
- 再加入 condition 后,目标损失函数为:\(L_{LDM}:= E_{\varepsilon(x),y, \epsilon \sim N(0, 1), t}[||\epsilon - \epsilon_\theta(z_t, t, \tau_\theta(y))||_2^2]\)
Unet
- 非常老的分割模型
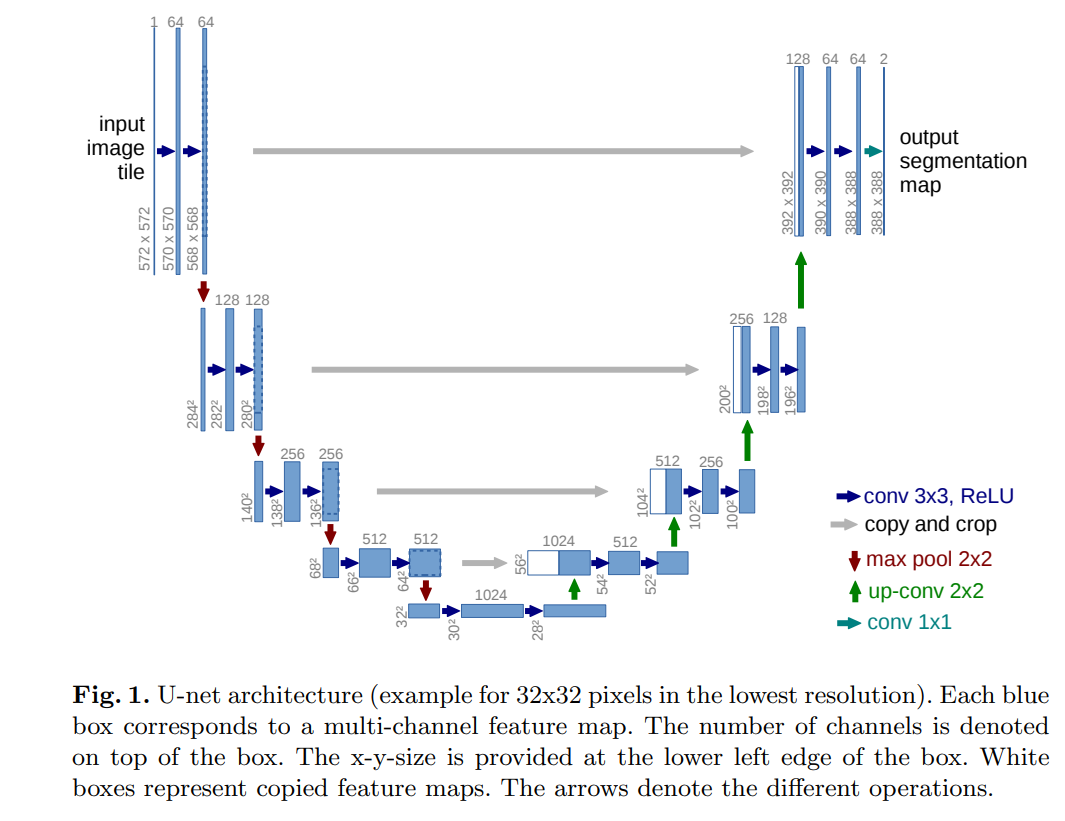
- 非常老的分割模型
Backbone
- 将 Unet 中的 CNN 替换成 transformer
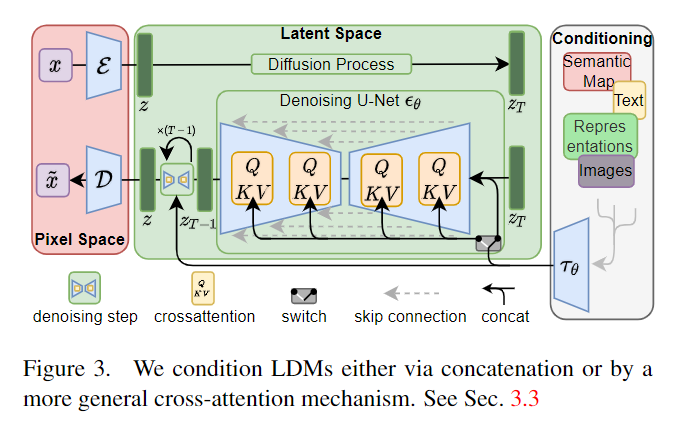
- 注意,有一半 Attention 为 cross attention:\(Q = W_Q^{(i)}\cdot \phi_i(z_t), K = W_K^{(i)}\cdot \tau_\theta(y), V=W_V^{(i)}\cdot \tau_\theta(y)\)
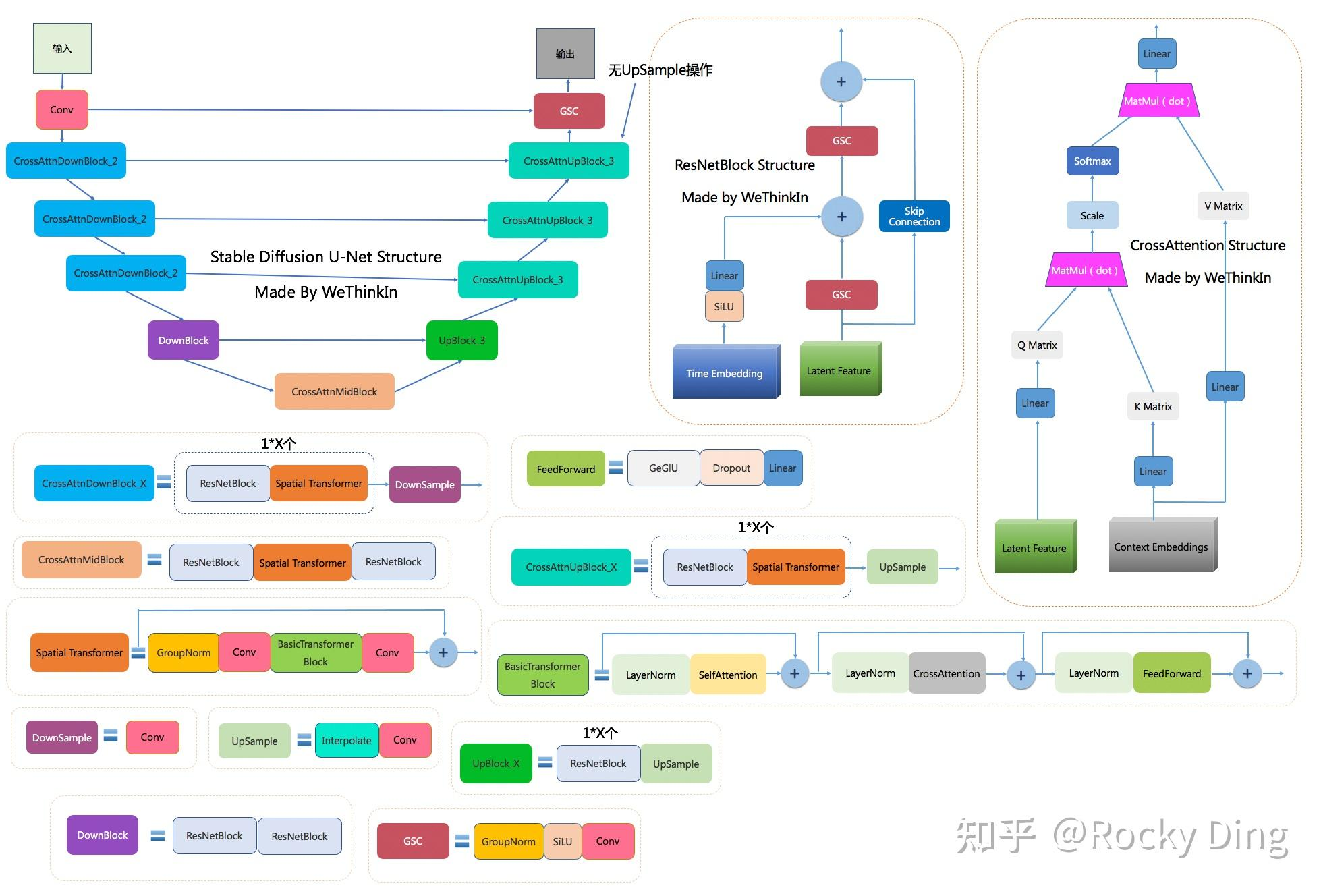
- 将 Unet 中的 CNN 替换成 transformer
github代码介绍
文件组织结构:
- LICENSE: 项目的许可证文件,说明了用户可以如何使用和分发该项目。
- setup.py:对整个 project 进行打包,可以看成为下载了一个 python 库到本地,与 pip install 效果相同
- Model_Card.md:模型的“技术规格说明书”,用于提供有关机器学习模型的详细信息,包括其性能、使用案例、潜在的偏差和限制等
- README.md:项目的“欢迎手册”,提供了项目的全面概览和使用指南
- environment.yaml:project 所需要的所有环境依赖配置,可用
conda env create -f environment.yaml直接对所有依赖进行下载 - main.py:Python
脚本,项目的入口点,可能包含设置、训练和评估机器学习模型的代码。例如可以使用
Pytorch.lightning 框架等

- configure/:模型,训练,以及推断的配置文件
- data/:有关数据,由于是文生图,这里包括了训练数据(train)的序号(index),验证数据(val)的序号,图片的标签(label, class);还有example,等等
- scripts/:通常包含用于执行特定任务的脚本,如 txt2img.py 用于文本到图像的采样,img2img.py 用于图像修改。这些脚本可能允许用户通过命令行接口运行模型并生成图像。
- models/: 一般包括模型和训练的 .py 代码等,可能也有 .yaml 配置文件,当然可能这些都放在以模型直接命名的文件夹里
Finetune with Lora
Hugging Face: Lora for SD reference; text_to_image finetune
Github script: train text_to_image lora
加噪训练:ICCV_Efficient Diffusion Training via Min-SNR Weighting Strategy
- 需要注意学习率的设置
- 训练脚本包括:参数设置解析,模型、数据、优化器加载配置,精度处理,加速器硬件设置,checkpoint保存,lora适配器微调,推理验证,日志记录,推送至hub,模型保存等等诸多步骤和技术。
- .py 关键代码解读如下:
args = parse_args():先解析参数,其中参数要在脚本 .sh 中设置,如下图所示: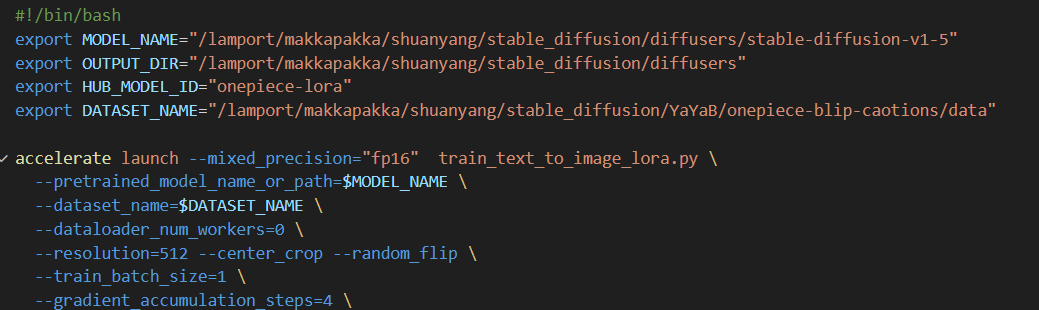 这里参数包括:
这里参数包括:--pretrained_model_name_or_path,--dataset_name,--resolution等等,参数定义的格式为: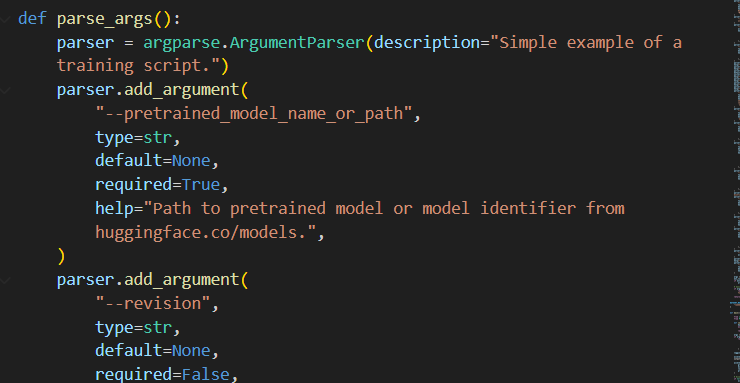
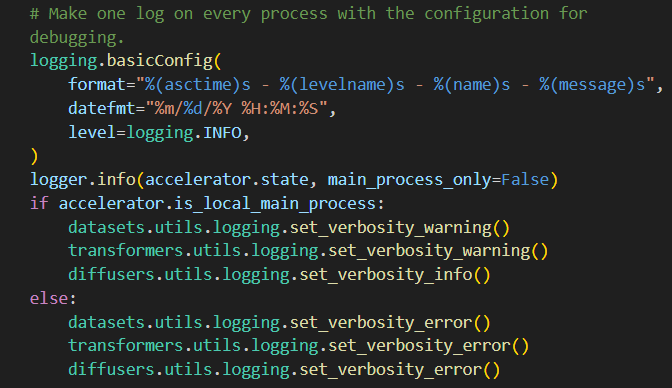
- log
日志记录,通常用于多进程或分布式训练的场景,以避免日志输出过多而导致的混乱。它确保只有主进程会记录INFO级别的日志,而其他进程则只记录更高级别的日志。
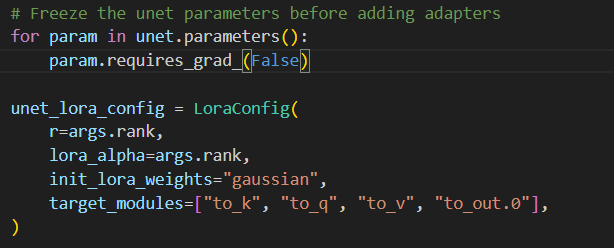
- 使用 Lora finetune 时冻结权重以及 Lora adapter
添加,同时设定训练精度,等等

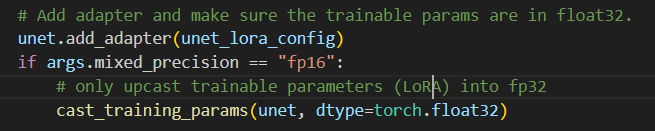
lora_layers = filter(lambda p: p.requires_grad, unet.parameters()):filter函数将只传递那些满足requires_grad为True的参数给lambda函数,最终返回一个迭代器,其中包含了所有需要梯度更新的参数。最终优化器如下: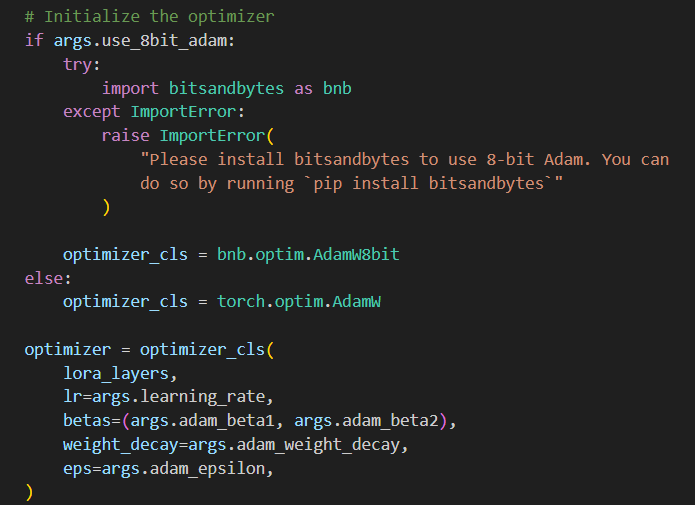
- TODO:实在写不动了
实验一:在服务器上跑lora
教程:README.md
先开启 myenv 环境!
- git clone diffusers,网络连接失败时可以直接下载压缩包,解压缩后通过 scp 传到服务器
- 安装各种环境以及依赖(参考教程步骤即可)
- acclerate initializ:使用 hugging face 提供的库,可以简化在各种设备和分布式配置上启动、训练和使用 PyTorch 模型的过程。它支持自动混合精度(包括 fp8),并且易于配置 FSDP(Fully Sharded Data Parallel)和 DeepSpeed 支持。注意:并不是所有配置都支持,实验中全部选择了 no 最后才跑通。 Accelerate; Reference
- 登录计算节点 玛卡巴卡 后,需重新开始 mynew 环境
- 更换 hugging face mirror 镜像源,使用 huggingface-cli 下载:huggingface-cli;模型不小,所以下载需要一定时间,因此可以用
sbatch 提交到计算节点运行程序(不能用srun,srun是交互式的)
 或者先在本地下载,再传到服务器中;并不是所有的 .bin
模型都要下载,只需要下载脚本中用到的即可(可以先不下载大文件,看运行的报错信息,仔一个一个补)。
或者先在本地下载,再传到服务器中;并不是所有的 .bin
模型都要下载,只需要下载脚本中用到的即可(可以先不下载大文件,看运行的报错信息,仔一个一个补)。 - 注意 .sh 脚本嵌套 .py 脚本,在 .sh 脚本中配置模型路径,数据集路径等参数
- 数据集,由于 example 中用到的宝可梦数据集被下架了,在hugging face中找到一个也是 'blip-captions' 的平替数据集 'cartoon-captions';data_path应该设置为 train_data 所在的文件夹;如果想用自己做的数据集,需要按照一定格式,参照:tutorials of data
- .sh 脚本注意事项:配置好模型、数据集、output 的路径,不推送至 hub,dataloader_num_workers=0;环境配置注意事项:不能使用过高版本python,这里 python=3.10, torch=2.2.2, torchvision=0.17.2, peft=0.6.1, cuda=12.2;其他:提前登录 wandb,这是一个可以记录训练过程的网站:wandb;image.convert需要更改,具体看脚本,多加一个 convert(image) 函数
- 实验结果:
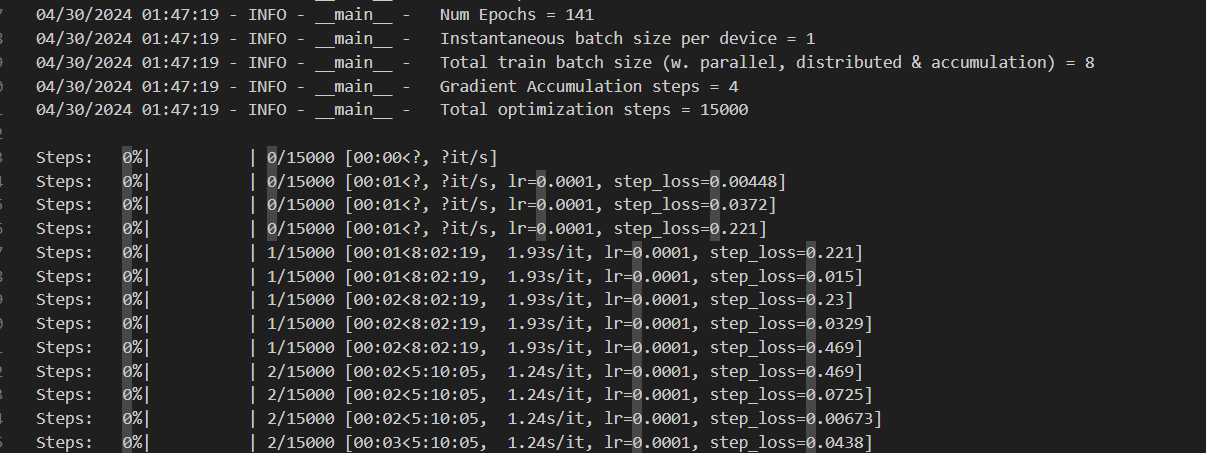 Lora-of-Stable-Diffusion-Report
Lora-of-Stable-Diffusion-Report
DiT
计划有变,由于UNet部署到芯片上太复杂了,不够规整,还有CNN,所以暂时又换成 DiT,回旋镖了,本来开学想做了,后面没做,现在又要帮忙做了。
整体结构
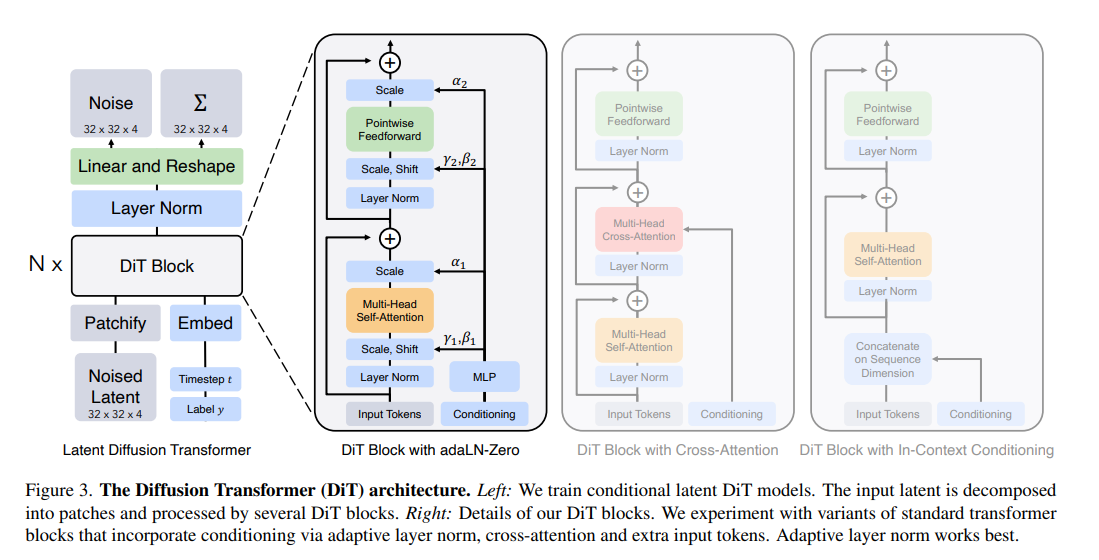
这里意思为,实验发现,左边 modulation attention 比 cross attention 更好,各种大小的网络信息如下:
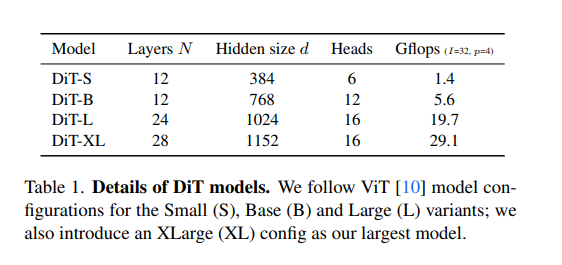
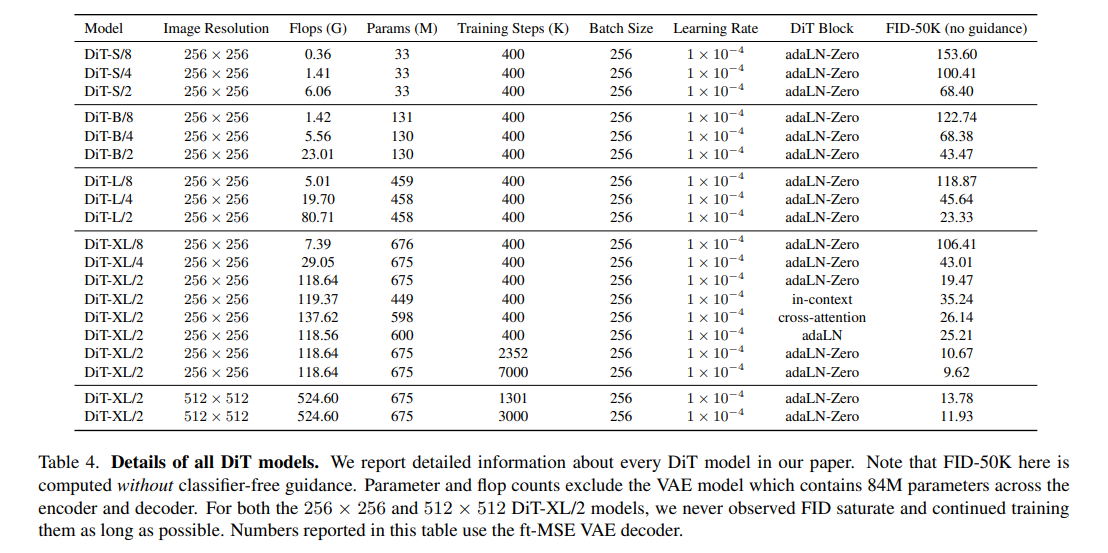
/2 是指 patch size = 2*2,
DiT Block
- 假设 batch = 1,先忽略
- image space [256, 256, 3] 转到 latent space [32, 32, 4]
- patchfy + posembedded 后,假设 patch = 2*2,则有 input [256, d],其中 d 即为 hidden size
- 以 DiT_S_2 为例,DiT Block 输入输出 flow 如下(画了一整晚,重操旧业了属于是。。。)
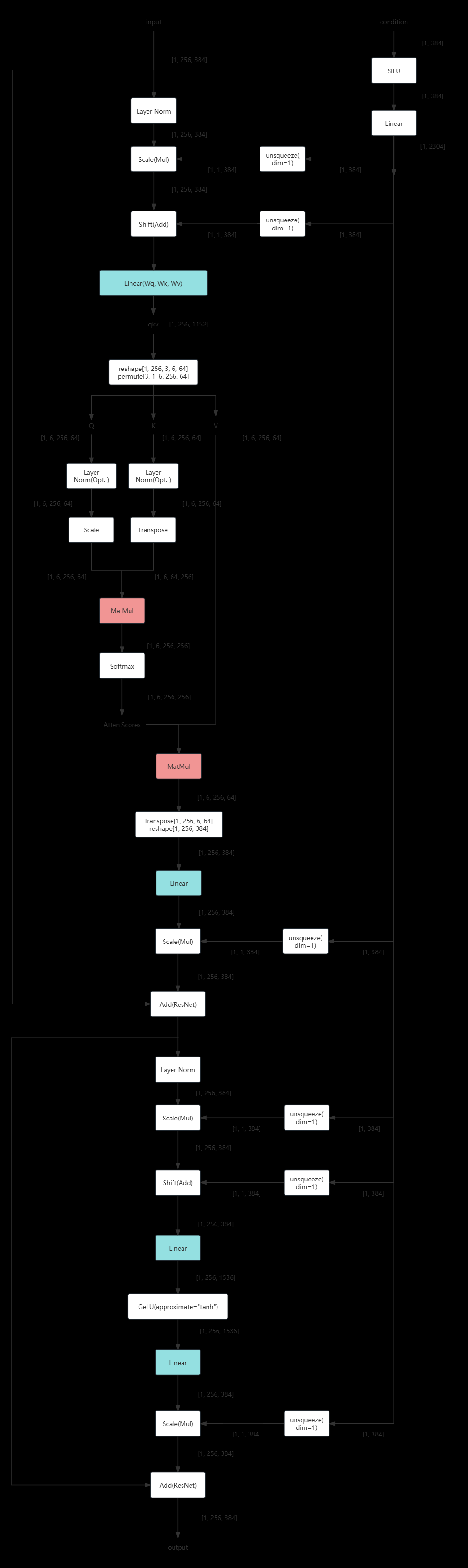
- Timeembedded,labelembedded,latent encoder,final layer 分析:TODO
DiT training
github上已有训练脚本代码,先简单解读一下部分内容:
分布式训练
1 | # Setup DDP: |
这段代码是用于设置PyTorch的分布式数据并行(DDP)环境的。DDP是一种用于在多个GPU上并行训练深度学习模型的技术。以下是代码的详细解释:
dist.init_process_group("nccl"):初始化进程组,这是DDP的基础。"nccl"是NVIDIA Collective Communications Library的缩写,它是一个用于在GPU之间进行高效通信的库。assert args.global_batch_size % dist.get_world_size() == 0:确保全局批处理大小可以被进程数整除。这是必要的,因为DDP将全局批处理大小平均分配给每个进程。rank = dist.get_rank():获取当前进程的排名。在DDP中,每个进程都有一个唯一的排名,用于区分不同的进程。device = rank % torch.cuda.device_count():确定当前进程应该使用哪个GPU。这里通过取余操作来分配GPU,确保所有进程都能均匀地使用可用的GPU资源。seed = args.global_seed * dist.get_world_size() + rank:设置随机种子。为了确保可复现性,通常会为每个进程设置一个唯一的随机种子。这里使用全局种子乘以进程数再加上进程的排名来生成每个进程的种子。torch.manual_seed(seed):设置PyTorch的随机种子,以确保当前进程中的随机操作(如参数初始化、数据洗牌等)是确定的。torch.cuda.set_device(device):告诉PyTorch当前进程应该使用指定的GPU。print(f"Starting rank={rank}, seed={seed}, world_size={dist.get_world_size()}."):打印出当前进程的排名、种子和总的进程数,以便于监控和调试。
通过这段代码,可以为DDP训练准备环境,确保每个进程都能够正确地使用GPU资源,并进行独立的随机操作。这对于在多个GPU上并行训练大型模型非常关键。
1 | # Setup an experiment folder: |
这段代码负责设置实验文件夹,它执行以下操作:
检查进程排名:只有当
rank等于0,即主进程时,才会执行创建文件夹的代码。这确保了实验文件夹和日志文件只被创建一次,避免了在分布式训练中由多个进程创建重复的文件夹或文件。创建结果目录:使用
os.makedirs创建一个名为args.results_dir的文件夹,该文件夹用于存储所有实验的子文件夹。exist_ok=True参数表示如果文件夹已存在,不会抛出错误。计算实验索引:通过计算在
args.results_dir路径下已有的文件和文件夹的数量来确定新的实验索引。glob(f"{args.results_dir}/*")会获取该目录下所有的文件和文件夹,然后通过len()计算数量。格式化模型名称:将命令行参数
args.model中的斜杠/替换为短横线-,以便于构建文件夹名称。创建实验文件夹:使用计算出的索引和格式化后的模型名称创建一个新的实验文件夹。索引是三位数,如果小于100,前面会用0填充。
创建检查点文件夹:在实验文件夹内创建一个名为
checkpoints的子文件夹,用于存储模型训练过程中的检查点。创建日志记录器:调用
create_logger函数创建一个日志记录器,如果rank不为0,则传递None作为参数,这意味着不会创建实际的日志文件。记录信息:如果
rank为0,使用日志记录器记录实验文件夹的创建信息。
这段代码的目的是为训练过程创建一个结构化的文件系统,其中可以存储模型的检查点、日志和其他相关数据。这有助于实验的组织和管理,尤其是在进行多次实验或使用分布式训练时。
创建模型并配置
除了普通的DiT,还需要将其包装在 EMA 中,同时还要加载创建扩散模型,以及 VAE 编码器
1 | # Note that parameter initialization is done within the DiT constructor |
数据加载处理
1 | # Setup data: |
这段代码设置了训练过程中使用的数据加载和预处理流程。以下是每个步骤的详细解释:
- 定义数据转换 (
transform):- 使用
transforms.Compose将多个转换操作组合在一起,用于对数据集中的每个图像进行预处理。 transforms.Lambda: 应用一个lambda函数center_crop_arr进行中心裁剪,确保图像大小符合args.image_size要求。transforms.RandomHorizontalFlip: 随机水平翻转图像,增加数据多样性。transforms.ToTensor: 将PIL图像或NumPyndarray转换为FloatTensor,并将图像的像素值从[0, 255]归一化到[0.0, 1.0]。transforms.Normalize: 对图像张量进行标准化处理,给出均值mean和标准差std,这里设置的均值和标准差都是[0.5, 0.5, 0.5],并且指定inplace=True表示直接修改输入张量,而不是返回一个新的张量。
- 使用
- 创建数据集 (
dataset):- 使用
ImageFolder类加载数据集,它会自动将文件夹中的每个子文件夹视为一个类别,并将图像加载为数据集中的一个样本。
- 使用
- 创建分布式采样器 (
sampler):DistributedSampler用于在分布式训练中确保每个进程只处理数据集的一部分,以提高效率并避免数据重复。num_replicas是参与训练的进程总数。rank是当前进程的索引。shuffle表示是否在每个epoch开始时对数据进行洗牌。seed用于确保在不同进程中洗牌的一致性。
- 创建数据加载器 (
loader):- 使用
DataLoader类来加载数据集,并提供给训练循环使用。 batch_size是每个进程应处理的批量大小,通过将全局批量大小除以进程数来计算。shuffle设置为False,因为在分布式训练中,洗牌的工作由DistributedSampler完成。sampler指定了使用分布式采样器。num_workers是用于数据加载的工作进程数。pin_memory表示是否将数据加载到CUDA固定内存中,这可以加快数据传输到GPU的速度。drop_last表示是否丢弃最后一个不完整的批次,这通常用于确保每个批次的大小一致。
- 使用
- 记录数据集大小:
- 使用
logger记录数据集的大小,这有助于监控和调试。
- 使用
通过这些步骤,代码完成了数据加载和预处理的设置,为模型训练提供了必要的数据输入。使用分布式采样器和数据加载器确保了在分布式训练环境中,每个进程只处理数据集的一部分,从而提高了训练的效率。
实验二:DiT training
原论文中数据集使用的是 Imagenet
1k,100G,太大了,捣鼓了很久,忽然发现,服务器里已经下好了数据集。。。
 开冲!!! 还是写个bash脚本吧
开冲!!! 还是写个bash脚本吧  注意:有个坑,hugging face连接不上,要先把vae下载到本地
注意:有个坑,hugging face连接不上,要先把vae下载到本地 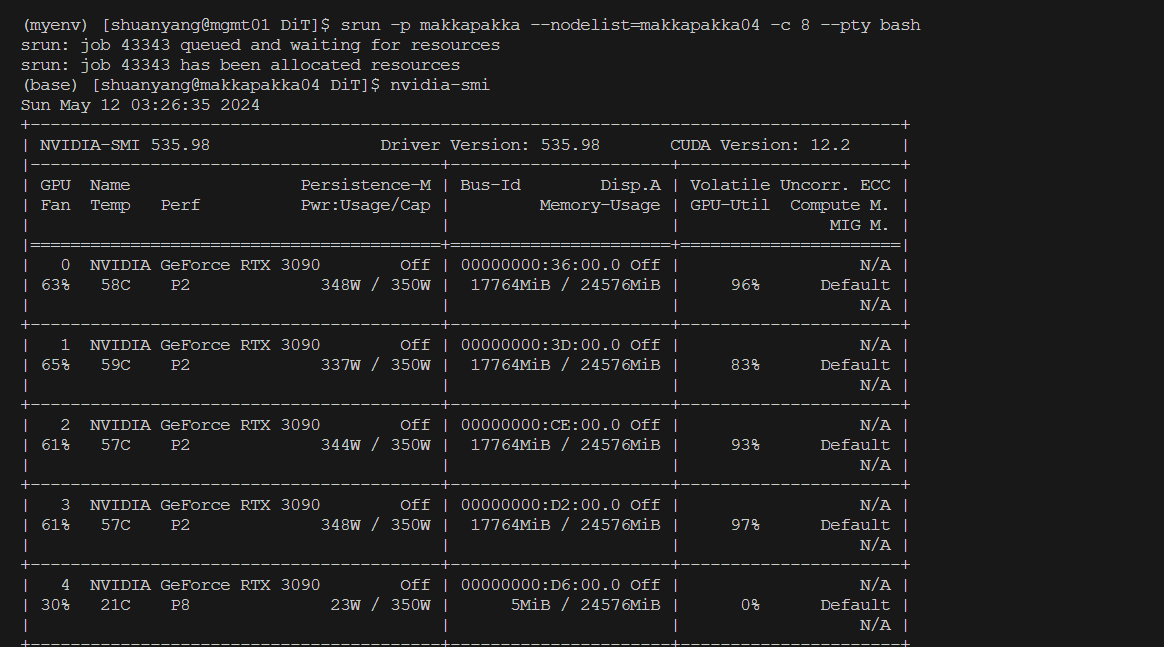 imagnet
太大了,需要四个gpu才能装下batch size=256 的训练
imagnet
太大了,需要四个gpu才能装下batch size=256 的训练 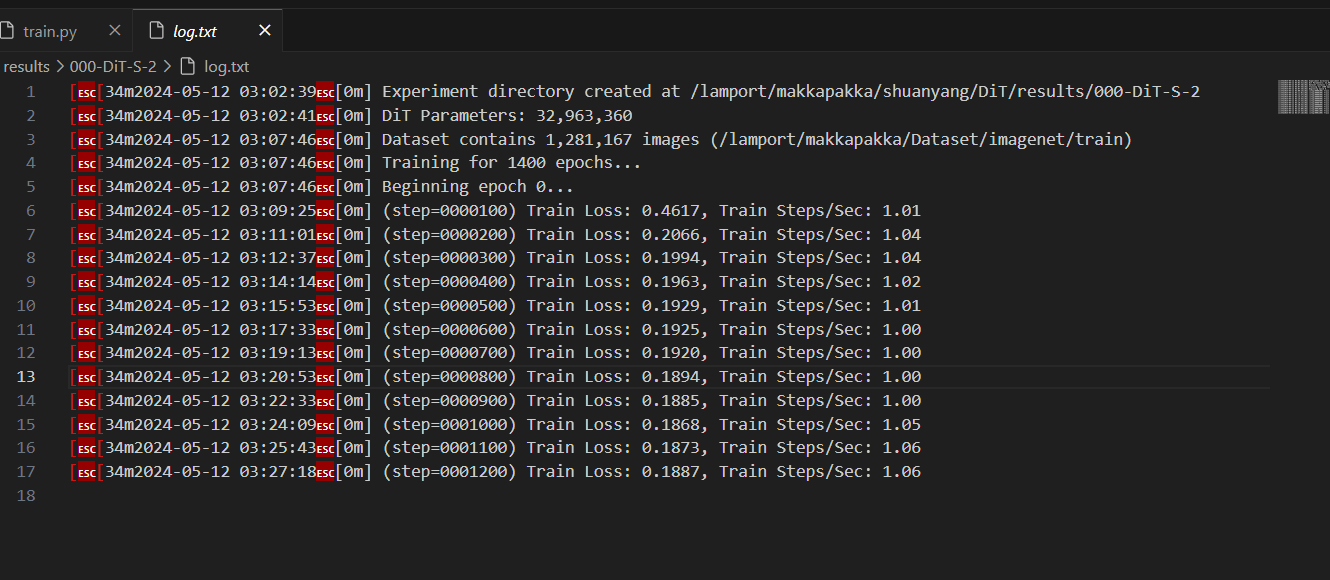 四个RTX3090一起训练,速度也并不快,算了下需要81天才能训完!!!哈人。。。
重新调整一下,训练周期 epoch=80,training steps 应该等于
400,436,假如1step/seconds,也需要4.63天
四个RTX3090一起训练,速度也并不快,算了下需要81天才能训完!!!哈人。。。
重新调整一下,训练周期 epoch=80,training steps 应该等于
400,436,假如1step/seconds,也需要4.63天
实验三:Lora finetune
使用 peft 库进行 finetune huggingface
- lora_config TODO