credit to 《Efficient Processing of Deep Neural Networks》
about this paragraph
介绍基本的DNN加速器设计的数据流,主要是对《Efficient Processing of Deep Neural Networks》做的笔记总结
Key Metrics
Energy consumption
- 减少数据的移动(data movement)
- 减少移动单位数据的代价
Performance in terms of throughput and latency
- 增加并行度(parallel)
- 减少PE空闲周期数
Area
Key Properties of DNN to Leverage
Data reuse
- Input feature map reuse 不同的滤波器(M),相同的输入
- Filter reuse 同一个滤波器,不同样本(N)的输入
- Convolutional reuse
- 每个filter的每个weight,复用 \(P\times Q\) 次,产生 \(P\times Q\) 个 output 像素点
- 若步长 U=1,则每个 input 的像素,一般会与 \(R\times S\) 个filter weight相乘,得到的 psum 属于不同的 output 像素
- Movement of Partial Sums 得到一个输出的像素点,有 \(C \times R \times S\) 个 psum 需要被 accumulated
DNN hardware design Consideratuions
设计一个 DNN 加速器,大致需要以下步骤:
- At design time
- dataflow(s)
- PE(process element)的数量,以及每个PE执行的MAC数量
- the memory hierarchy,包括存储的级数(levels),以及每一级的容量(capicity)
- the allowed pattern of NoC(Network on-chip)
- At mapping time 将 DNN 网络有效的映射到硬件加速器上
- At configuration time
- At run time
Data reuse
- Temporal reuse
- Temporal reuse occurs when the same data value is used more than once by the same consumer
- It can be exploited by adding an intermediate memory level to the memory hierarchy of the hardware, where the intermediate memory level has a smaller storage capacity than the level that acts as the original source of the data
- For exploiting temporal reuse, the reuse distance is defined as the number of data accesses required by the consumer in between the accesses to the same data value, which is a function of the ordering of operations.
比如,以下1-D卷积,filter weight
的存储有两级,L0存放着所有权重,L1仅能存放数量为一的权重,如(d),则两种不同的计算顺序(order),其
weight reuse distance 也不同,(output reuse distance 也不同)。 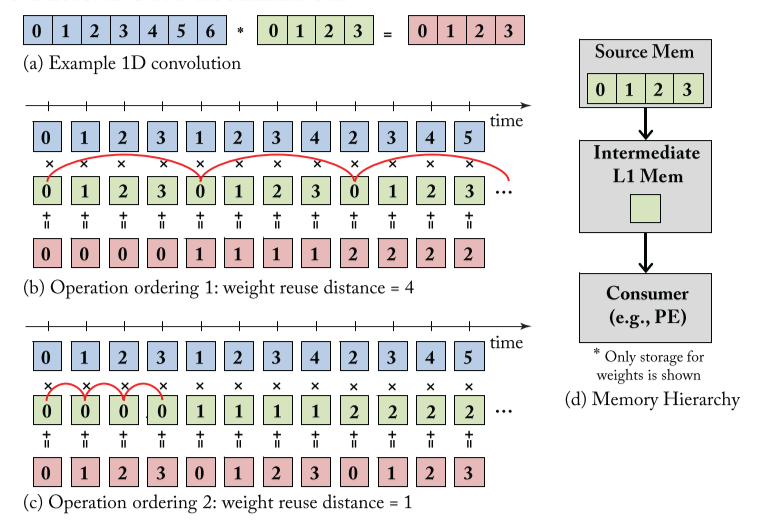
因此,重要的是,reuse distance, 即 the processing order
- Spatial reuse
- Spatial reuse occurs when the same data value is used by more than one consumer (e.g., a group ofPEs) at different spatial locations ofthe hardware.
- It can be exploited by reading the data once fromthe source memory level andmulticasting it to all ofthe consumers.
- For exploiting spatial reuse, the reuse distance is defined as the maximum number of data accesses in between any pair ofconsumers that access the same data value, which is again a function of the ordering of operations.
比如,以下1-D卷积,有数量为4的 consumers(PE),可用于同时计算 MAC,
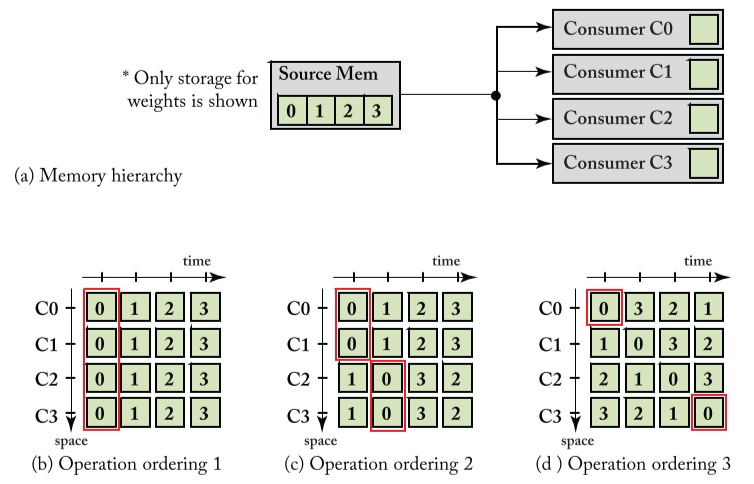
因此,重要的是,reuse distance, 即 the designs of parallel
同时需要注意,spatial reuse 需要 Noc 来支持,与 Memory 的层级和带宽 (bandwidth) 都有关系。
data reuse 设计关键点
- Process order
- Parallel computation
- Data tiling
- 同时考虑 bandwidth, Memory hierarchy 等
算法(Algorithm)描述
- loop nests
- WS, IS, OS
- for
比如,使用伪代码描述下面一个1-D卷积,循环越靠近外层,说明其静态性(stationary)越高,

 以图 (a) 的 WS 为例,完成本次卷积所有操作的 0-35 次 cycle 里面,追踪每次
cycle 用到的数据的索引 (Index) 如下图:
以图 (a) 的 WS 为例,完成本次卷积所有操作的 0-35 次 cycle 里面,追踪每次
cycle 用到的数据的索引 (Index) 如下图: 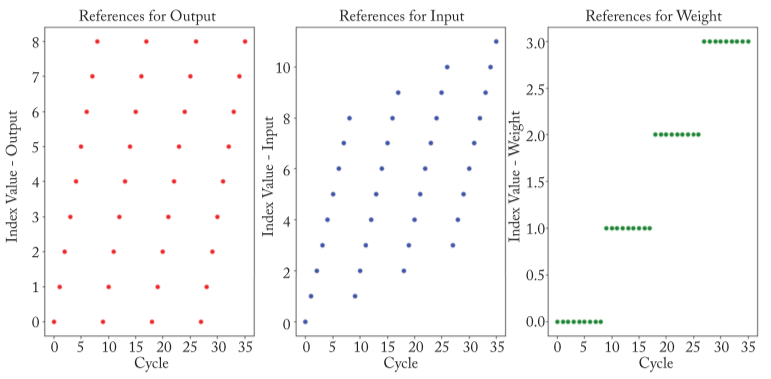
parallel-for
比如,对上述的 WS 加入对 权重
的并行设计,即将权重的循环更进行的划分(Tiling):  每次执行的状况如下:
每次执行的状况如下: 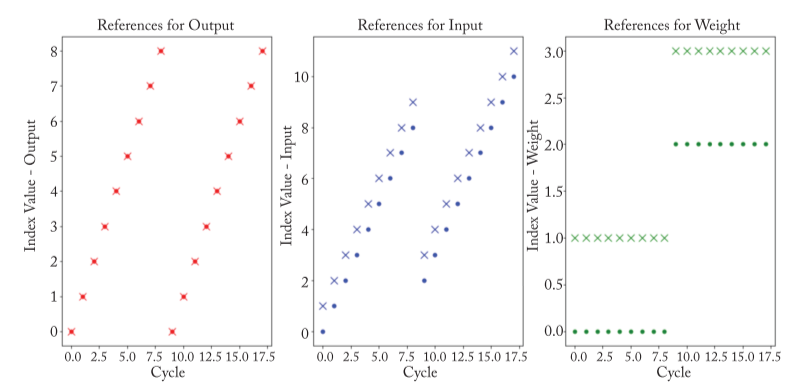 可将之与无并行进行对比。 设计并行时,既要考虑 PE 数量,又要考虑 Memory
的容量与带宽,还要考虑划分是否整除,等等。
可将之与无并行进行对比。 设计并行时,既要考虑 PE 数量,又要考虑 Memory
的容量与带宽,还要考虑划分是否整除,等等。
A dataflow only defines the following aspects of a loop nest: (1) the specific order of the loops to prioritize the data types; (2) the number of loops for each data dimension to describe the tiling; and (3) whether each of the loops is temporal (for) or spatial (parallel-for).
Dataflow Taxonomy
Weight Stationary(WS)
- The weight-stationary dataflow is designed to minimize the energy consumption of reading weights by maximizing the reuse ofweights from the register file (RF) at each PE
- The processing runs as manyMACs that use the same weight as possible while the weight is present in the RF
- The inputs and partial sums must move through the spatial array and global buffer. The input feature map activations are broadcast to all PEs and then the partial sums are spatially accumulated across the PE array.
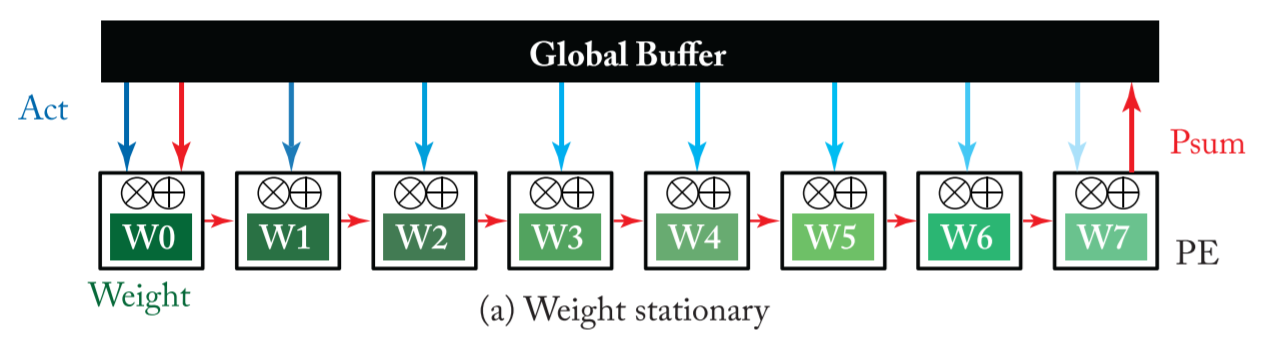
比如,nn-X (also called neuFlow),它有:
- 8 个 2-D CONV engines
- 每个 engine 有 100 个 PE(因此可以实现最多\(10 \times 10\)的卷积)
- weight 在每个 PE 里保持静态不变
- input 广播(broadcast) 至每个 PE 中
- 由于每次(cycle)所广播的只有一个 input 像素,为保证时序正确性,需要添加寄存器以控制 psum 的相加
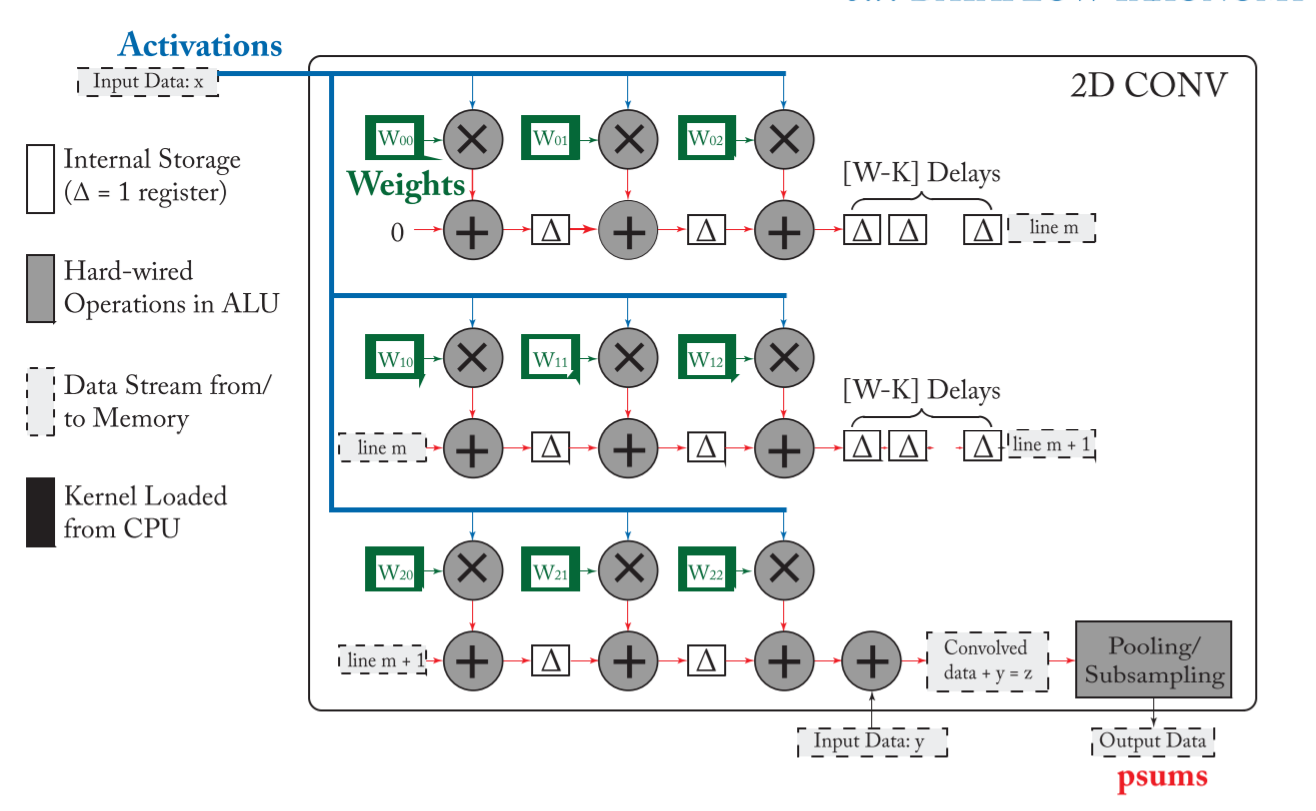
再比如,Nvidia’s Deep Learning Accelerator
(NVDLA),与前面不同的是,psum 是一列列相加(不同列不同的 filter
,每一行则对应不同的 input(and filter) channel 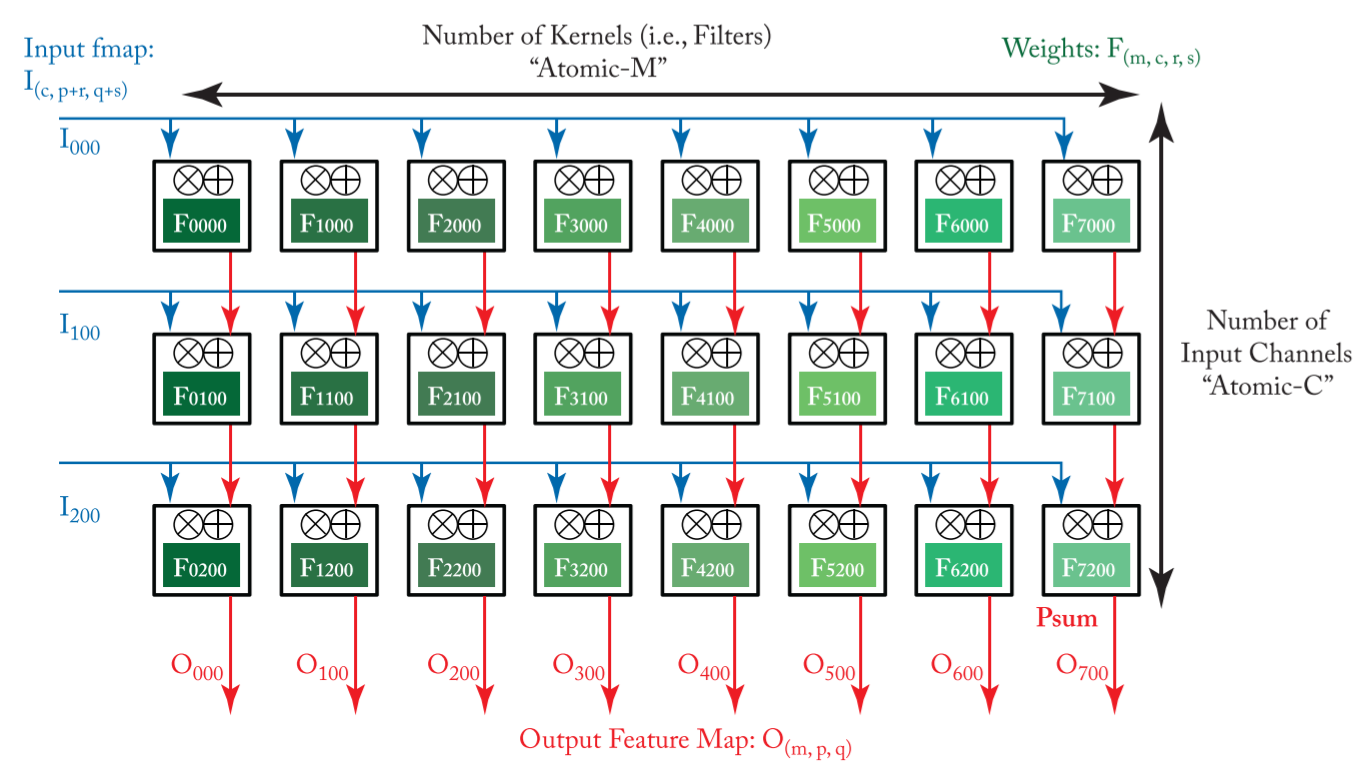 其算法如下:
其算法如下: 
Output Stationary(OS)
- The output-stationary dataflow is designed to minimize the energy consumption of reading and writing the partial sums.
- In order to keep the accumulation of partial sums stationary in the RF, one common implementation is to stream the input activations across the PE array and broadcast the weights to all PEs in the array from the global buffer.
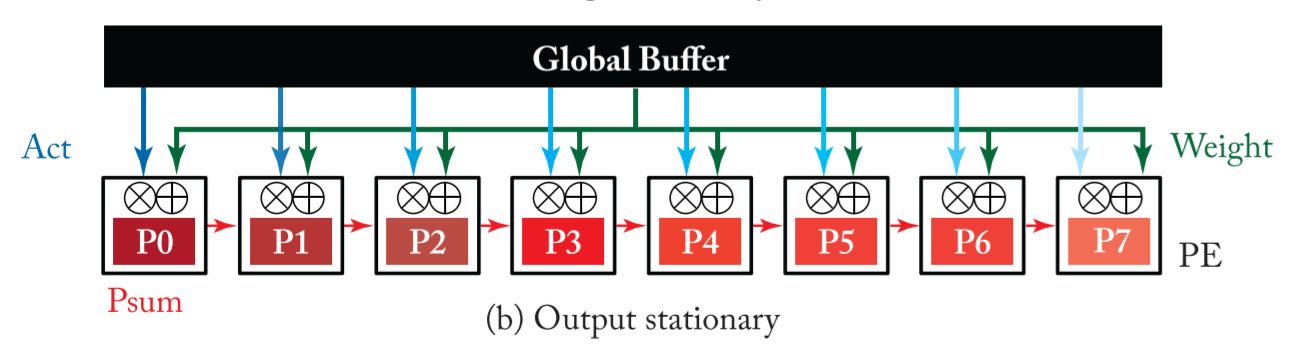
可以选择不同的 output 像素保持 stationary 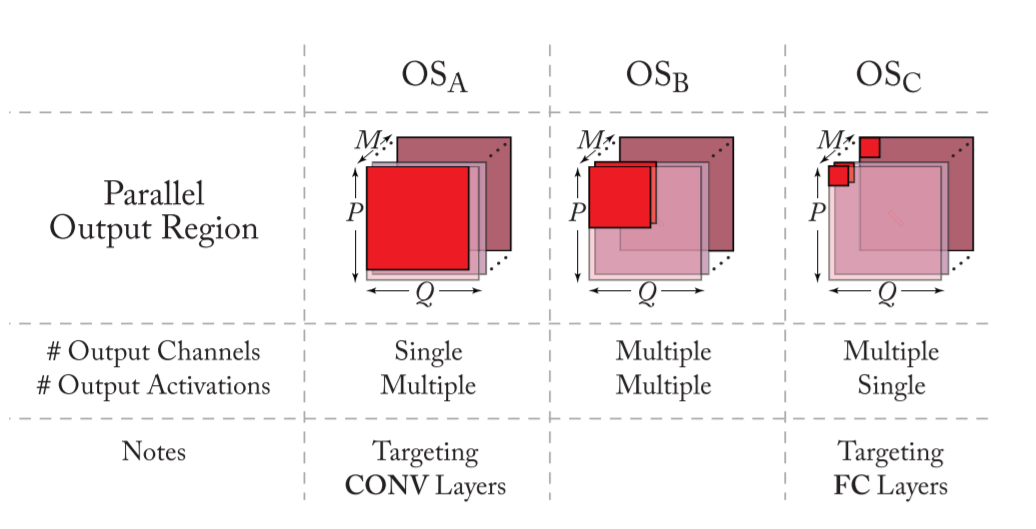
未完待续。。。
Input Stationary(IS)
- Similar to the previous two dataflows, the input-stationary dataflow is designed to minimize the energy consumption ofreading input activations.
- With minimized reuse distance, each input activation is read from DRAM and put into the RF ofeach PE and stays stationary for further access. Then, it runs through as many MACs as possible in the PE to reuse the same input activation.
- While each input activation stays stationary in the RF, unique filter weights are uni-cast into the PEs at each cycle, while the partial sums are spatially accumulated across the PEs to generate the final output activation.
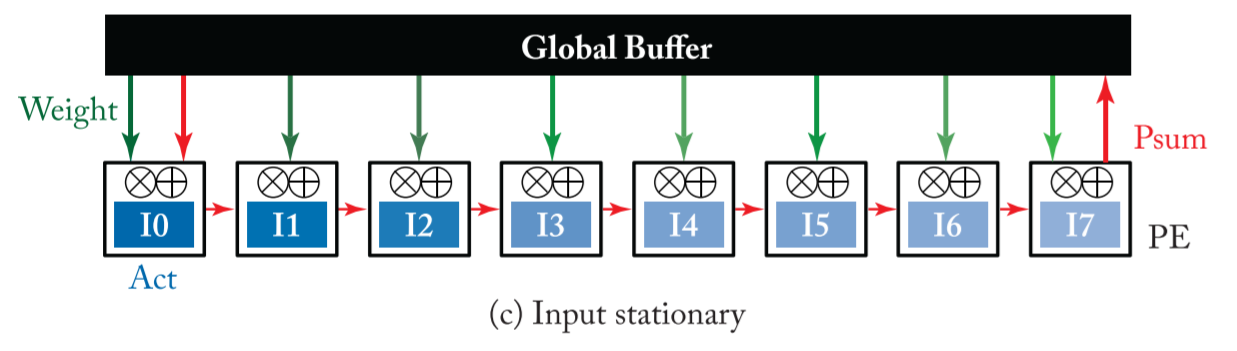
未完待续。。。
Row Stationary(RS)
A row-stationary dataflow is proposed in Eyeriss, which aims to maximize the reuse and accumulation at the RF level for all types of data (weights, input activations, and partial sums) for the overall energy efficiency.
- 1-D CONV:
weight stationary inside the RF streams the activations into PE 比如下面 S=3,W=5,U=1 的卷积,得到 F=3 的 output,需要三个 step
值得注意的是,filter 与 input 流进 PE 与 output 流出,都应使用 FIFO 进行正确的时序控制
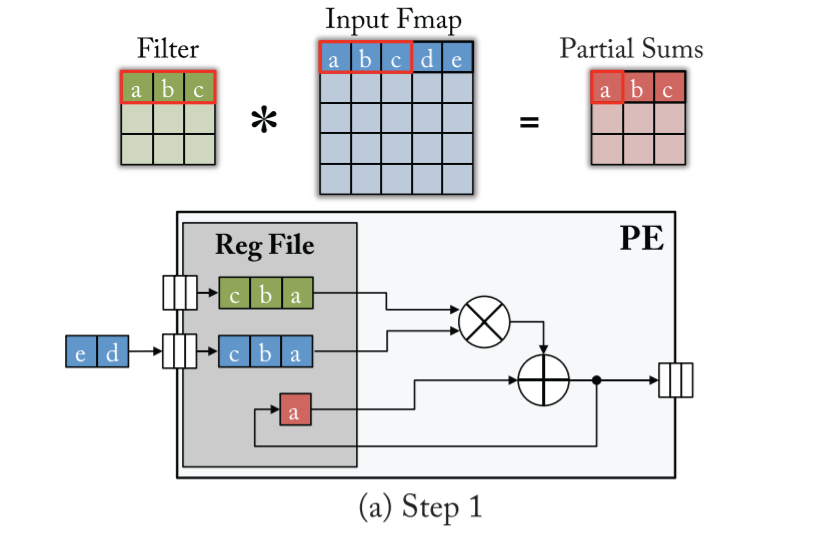
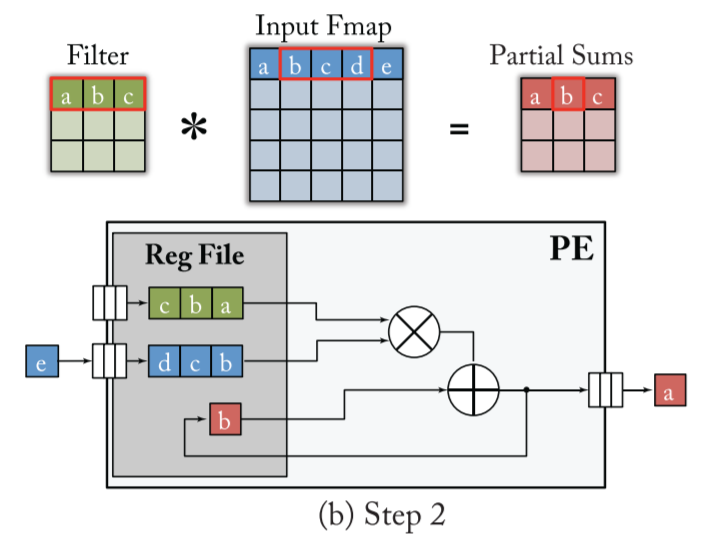
- 2-D CONV:
由 多个 1-D 卷积组成, 比如下面 R=3, S=3, H=5, W=5, U=1 的卷积,得到 E=3, F=3 的 output
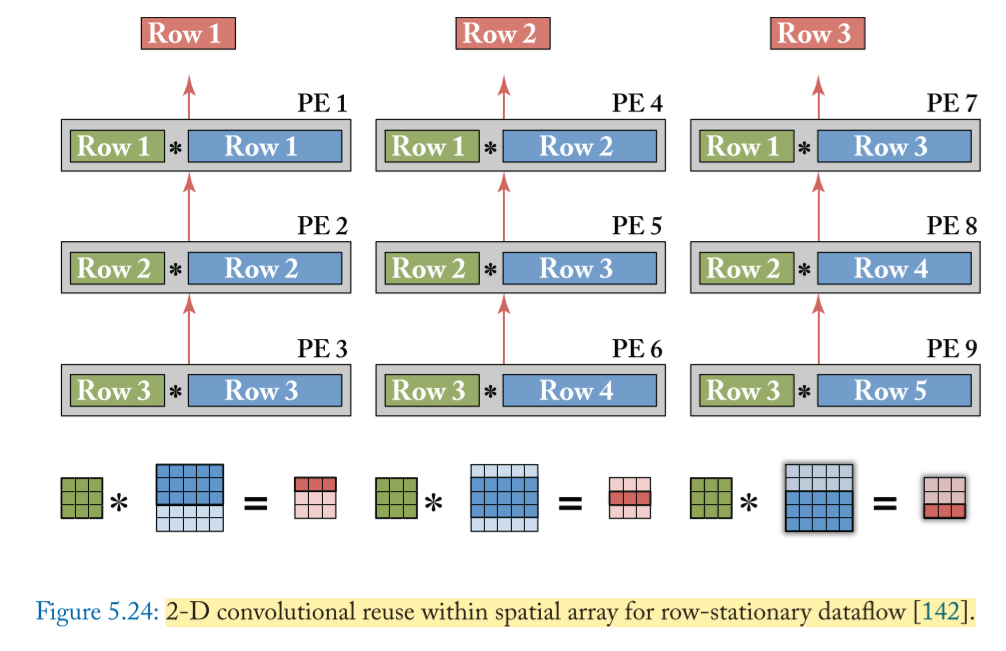
- 在这个例子中,每一行 output 的产生,仍然需要 3 个 steps
- 而每一个 step 所产生的一个 output 像素点,都需要 3 row 的 1-D 卷积同时进行,然后将对应的 psum 相加(accumulated) 得到
- 得到所有行的 output 需要进行 3 次上述的操作
- 由上述例子可得:每一 Row 的 filter weights 在同一 Row 的 PE 上复用;每一 ROW 的 inputs 则按 相同的 diagnal 复用; 每一 col 的 PE 得到的 psum 要进行相加
- Higher-dimensional CONV:
N, M, C三个维度 Interleaving or concatenating 有下面三种复用:(a) filter reuse of multiple (N) input (b) input reuse of multiple (M) filters (c) output reuse of multiple filter weights and inputs (C)
对应的techniques可以是:(a) concatenating (b) interleaving (c) interleaving
存在问题:PE 阵列的大小是 fixed 的,应如何将不同 shape 的 DNN layer 映射呢?两大techniques:(a) replication (b) folding
总的思想是:提高 PE 的利用率 注意:不使用的 PE 应关上使其耗能减少。
- 硬件结构支持
- PE array
- Mapping and Configure
- Noc
- Memory hierarchy
Other Stationary
- Since the stationariness of a dataflow is only relative to a specific level of memory hierarchy, different stationariness can be used at each level of the memory hierarchy.
- From the perspective ofa loop nest, it involves tiling the various data types into multiple levels and then reordering the loops at different levels to prioritize different data types.
- For example, ifthere are K levels ofmemory hierarchy, both dimension Q and S in the loop nest ofFigure 5.8a can be further divided up into K loops (i.e., for the open ranges [Q0, QK) and [S0 to SK) ) and then reordering the loops independently from loop level 0 to level K - 1.
- This also implies that smaller DNN accelerator designs can be further combined together with a new level ofmemory to form a larger accelerator.
- The key to these designs is to propose flexible NoCs and support various memory access patterns in order to execute different dataflows that have different numbers ofloop levels and loop ordering in the loop nest
- 上面的讨论基于一个layer无法在PE中一次就计算完成,然而,若layer足够小,或PE足够大,还需讨论跨层处理、流水线等技术
DNN Accelerator Buffer Management Strategies
可大致分为四种结构:
- implicit/explicit(隐式/显式): 指的是利用工作负载知识来控制数据缓冲决策的程度
- coupled/decoupled(耦合/解耦):
指的是内存响应和请求是往返的(请求-响应)还是前向的(数据自动推送给使用者)
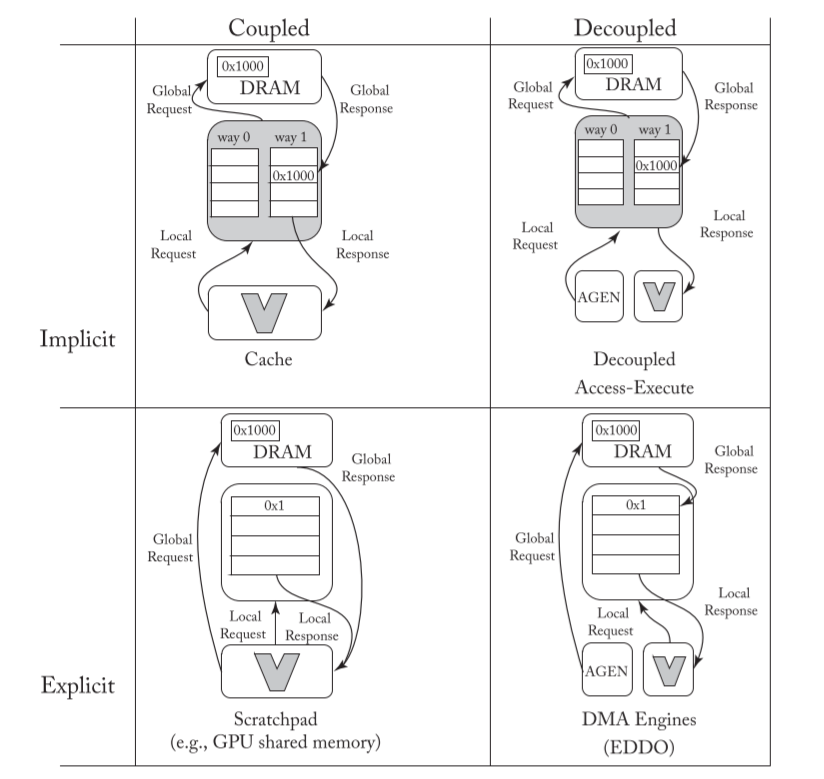
EDDO(Explicit Decoupled Data Orchestration)
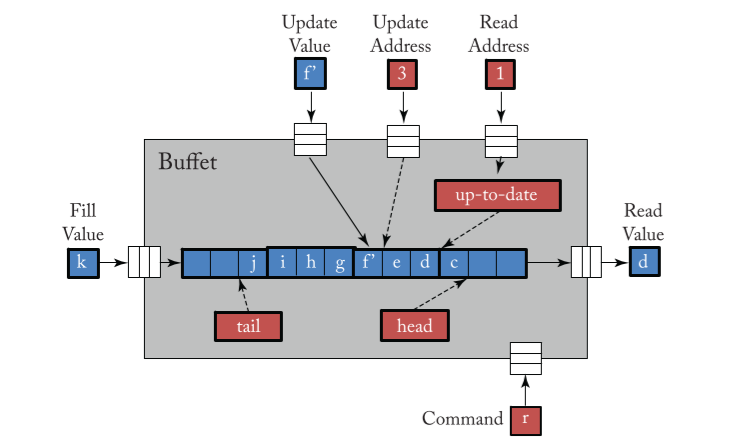
buffet
- FIFO
- fill: from an NoC link into the tail
- read: read command + read address(offset of head)
- update: read + update command + update address
- shrink: removes a given number ofvalues from the head of the buffet
by adjusting the head pointer
比如,实现一维卷积时,读入 input
数据的序列为:0,1,2;1,2,3;2,3,4…… 而 psum
的读入并更新的序列应对应为:0,0,0;1,1,1;2,2,2…… 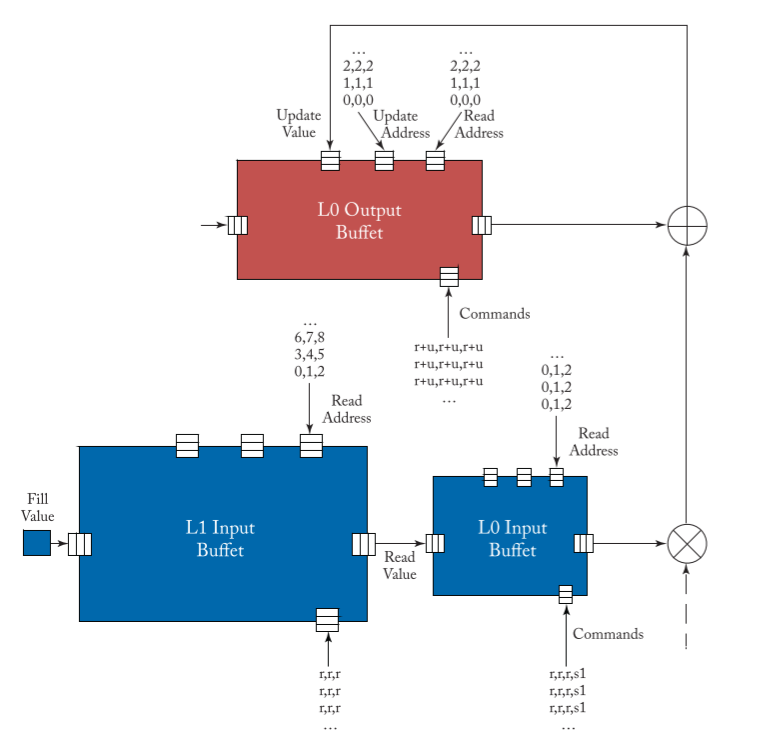
Flexible Noc design
要考虑的是:
- support processing with high parallelism by efficiently delivering data between storage and datapaths; (2) exploit data reuse to reduce the bandwidth requirement and improve energy efficiency; and (3) can be scaled at a reasonable implementation cost.
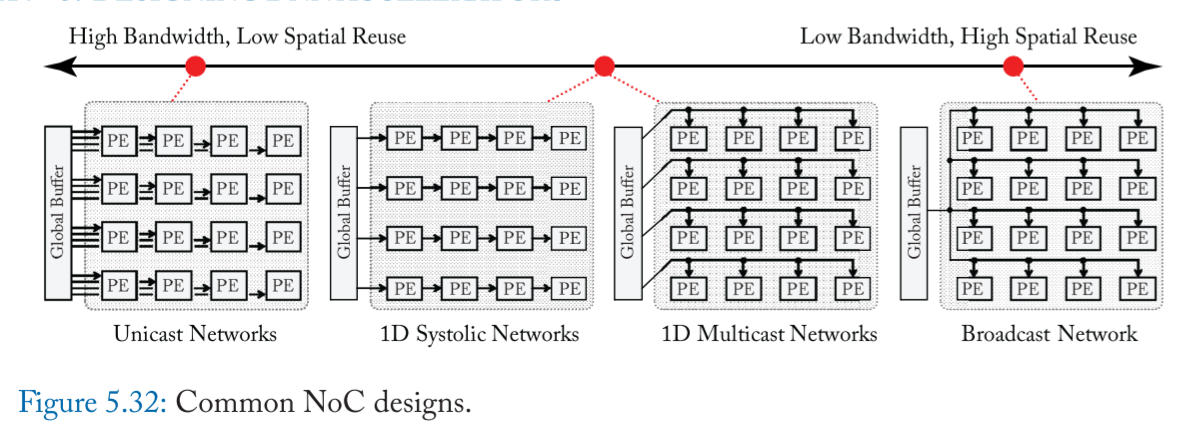
比如: 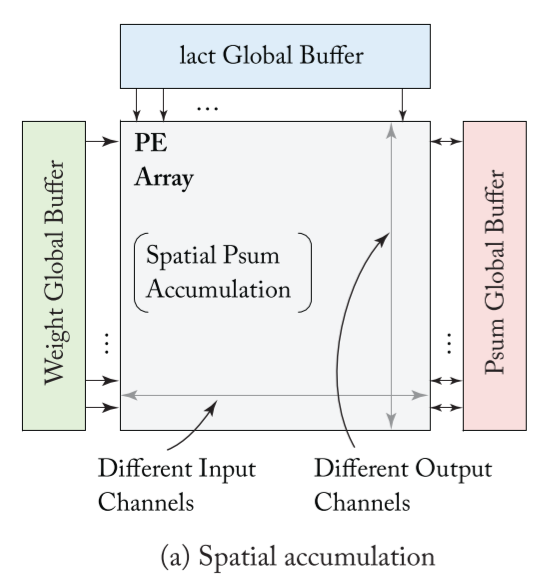
- 每一 row 的 weight 来自不同的 filter (M),同一 row 中的 weight 来自不同的 channel(C),stationary
- 每一 col 的 input 来自不同的 channel(C)
- 同一 row 的 psum 相加后在传输到 psum buffer
- input activations (iacts) are reused vertically and partial sums (psums) are accumulated horizontally
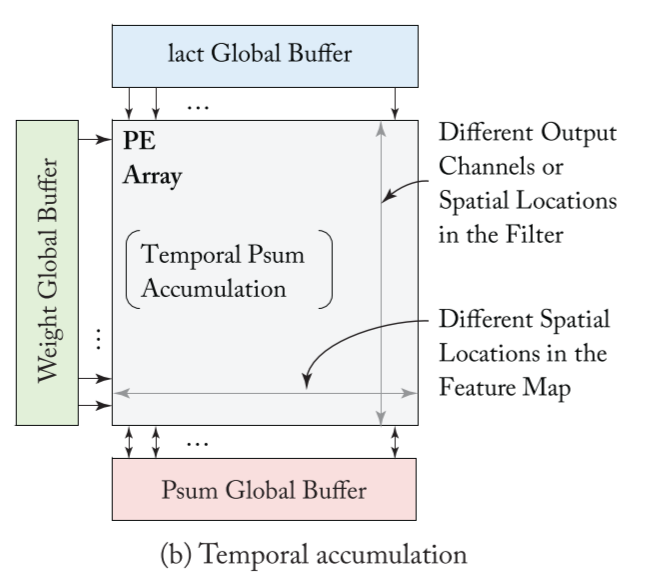
- 每一 row 的 weight 来自不同的 filter (M) 或者 同一 filter 但不同的位置
- 每一 col 的 input 都不同空间位置 (H, W)
- input activations (iacts) are reused vertically and weights are reused horizontally
三种通信方式的优缺点: 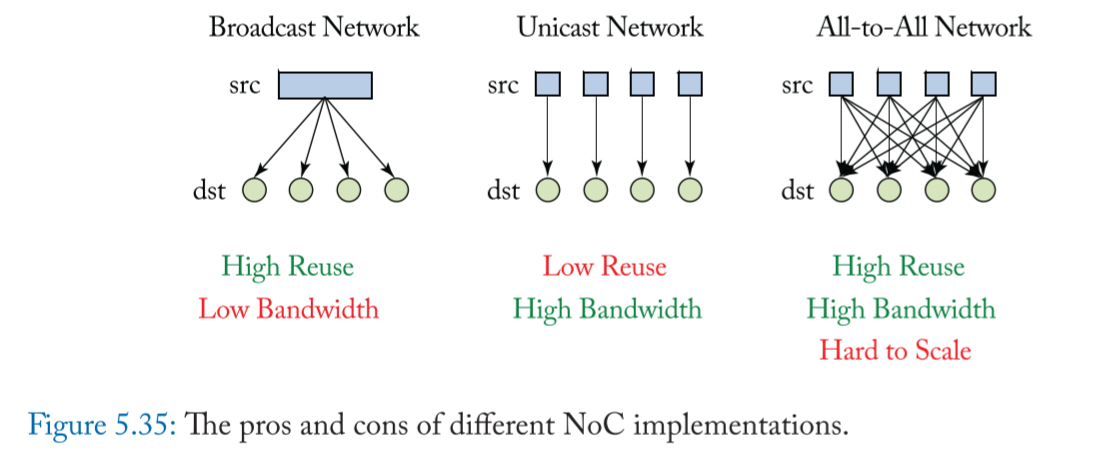
Hierarchical Mesh Network
hierarchical mesh network(HM-NoC) 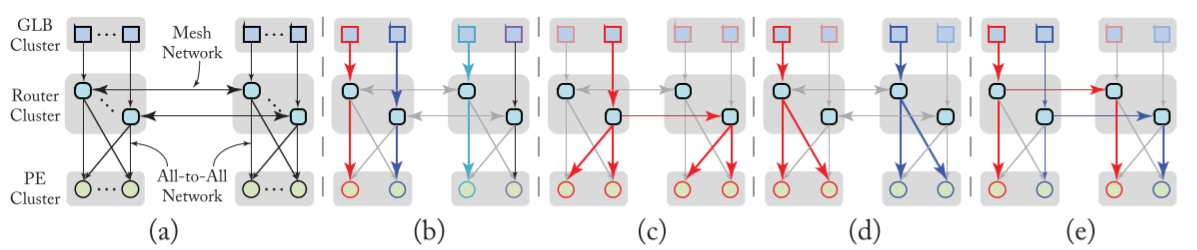
- 2 levels
- 4 modes
例子: 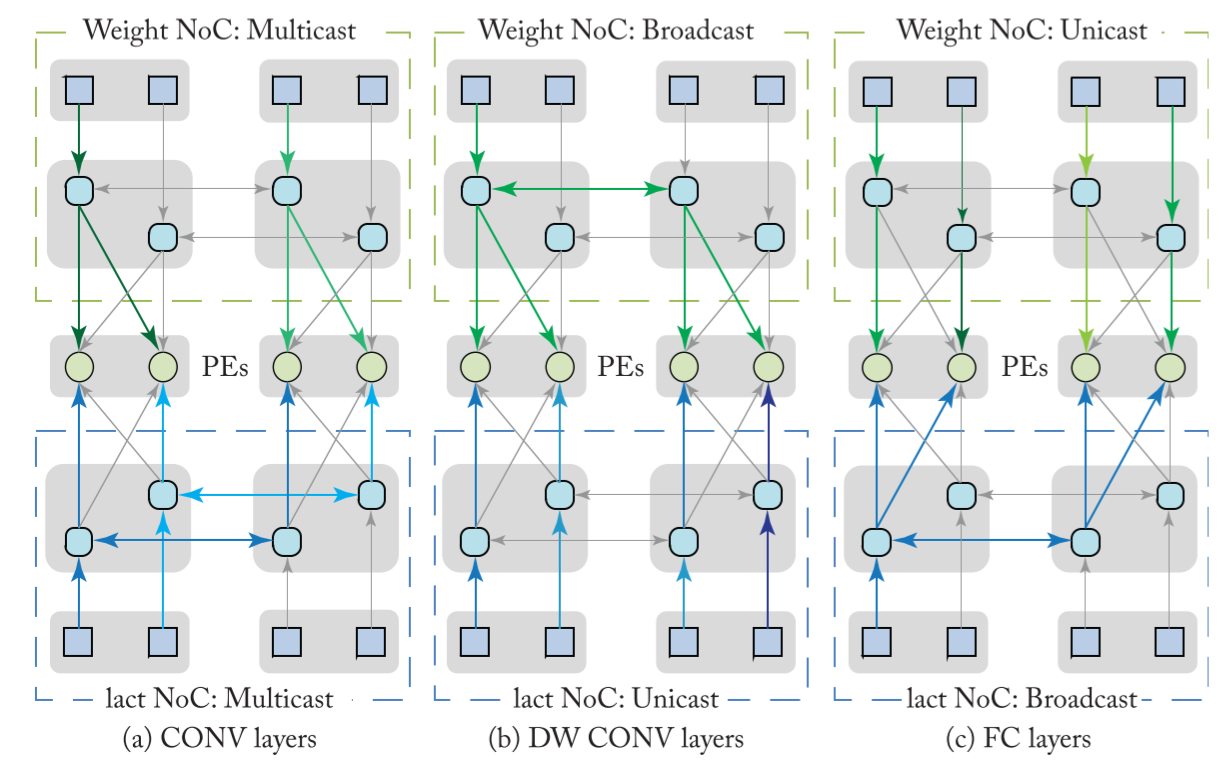
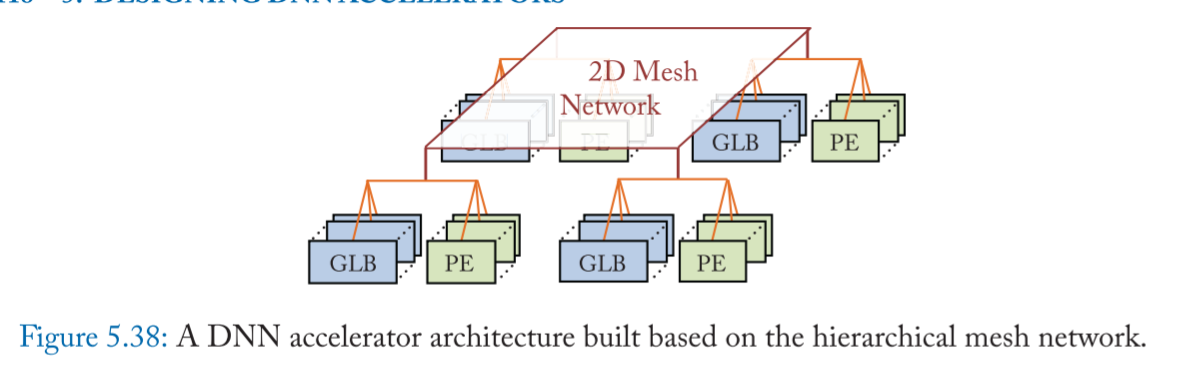
mapping
In the processing ofDNNs, the mapper translates the desired DNN layer
computation (i.e., problem specification) along with its shape and size4
into a hardware- compatible mapping for execution. 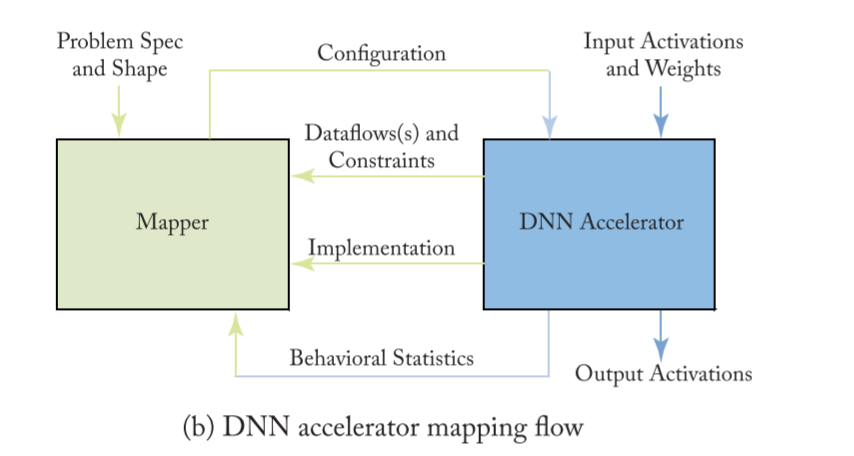
类比cpu: 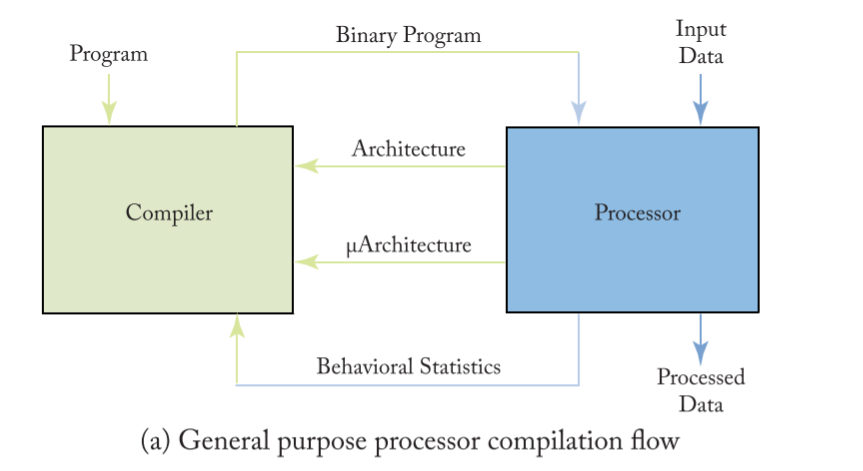
mapper 框图: 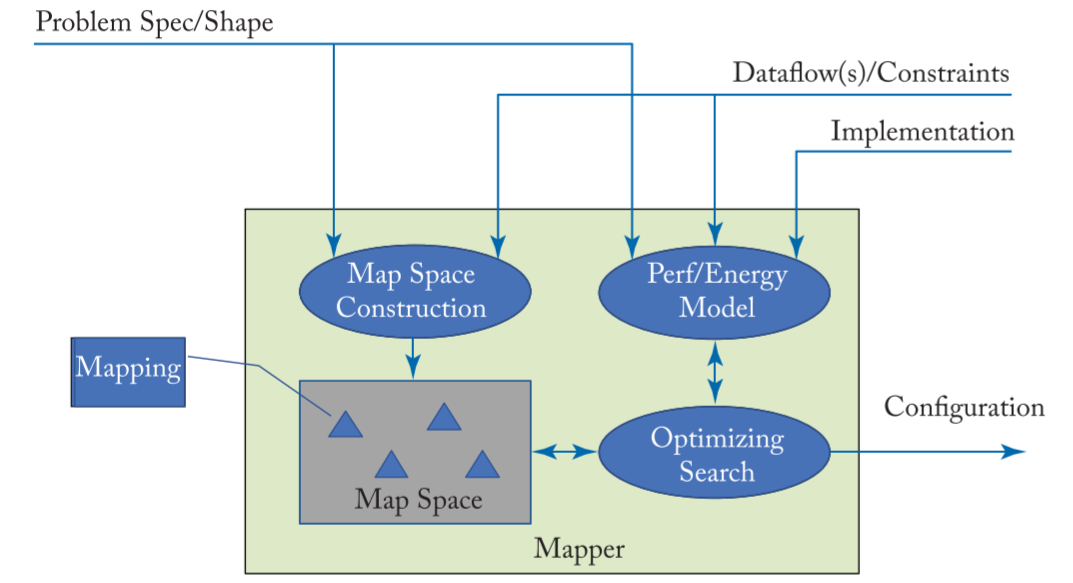
根据 Problem Spec/Shape 以及约束 Dataflow(s)/Constraints 在解集 mapper space 里面搜索出最优解,然后对 DNN Accelerator 进行配置
映射的算法可以用 loop nest 来表示,比如 
