credit to 《人工智能芯片技术白皮书2018,清华大学》《AI 芯片前沿技术与创新未来,张臣雄》 《2022亿库关于中国ai芯片行业的调研》
当英伟达成为全球首家市值超过1万亿美元芯片公司时,便意味着AI芯片的的热潮前所未有地席卷各行各业,成为人工智能时代的最重要的物理基石——无芯片,不 AI
什么是 AI 芯片?
定义:从广义上讲只要能够运行人工智能算法的芯片都叫作 AI 芯片。但是通常意义上的 AI 芯片指的是针对人工智能算法做了特殊加速设计的芯片,现阶段,这些人工智能算法一般以深度学习算法为主 (比如包括 DNN, CNN, RNN, LSTM, GAN, Transformer)
- 研究如何设计出高效的硬件友好型的智能算法
- 研究如何将这些算法有效可靠地在芯片上实现
AI 芯片本身处于整个链条的中部,向上为应用和算法提供高效支持,向下对器件和电路、工艺和材料提出需求。

AI 芯片的种类
按类型
经过软硬件优化可以高效支持 AI 应用的通用芯片
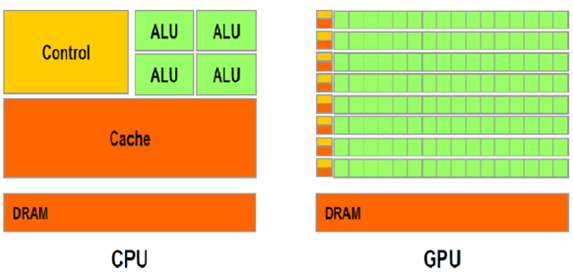
GPU
GPU是单指令、多数据处理,采用数量众多的计算单元和超长的流水线,主要处理图像领域的运算加速。GPU是不能单独使用的,它只是处理大数据计算时的能手,必须由CPU进行调用,下达指令才能工作。为此开发的专用编程系统CUDA,能够帮助工程师们运行数万个并发线程和数百个处理器核。 高度并行计算,软硬件协同
TPU, NPU
侧重加速机器学习(尤其是神经网络、深度学习)算法的芯片
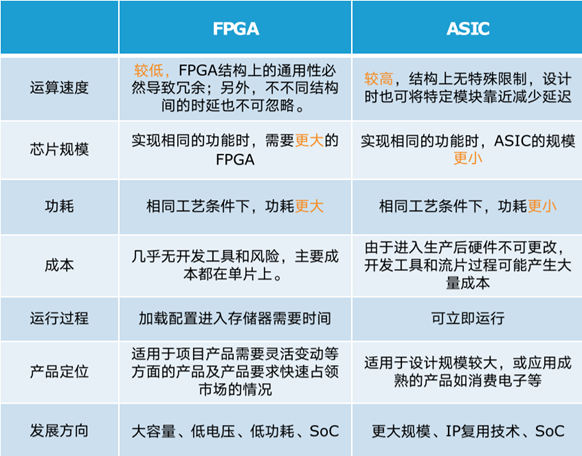
FPGA
可编程逻辑门阵列,是一种“可重构”芯片,具有模块化和规则化的架构,主要包含可编程逻辑模块、片上储存器及用于连接逻辑模块的可重构互连层次结构。
ASIC
特定用户要求和特定电子系统的需要而设计、制造的集成电路。
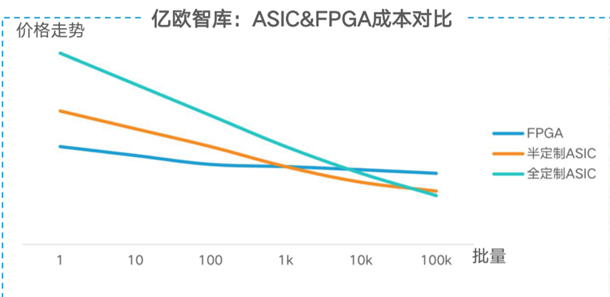
两者对比 FPGA具有开发周期短,上市速度快,可配置性等特点,目前被大量的应用在大型企业的线上数据处理中心和军工单位。ASIC一次性成本远远高于FPGA,但由于其量产成本低,应用上就偏向于消费电子,如移动终端等领域。
受生物脑启发设计的神经形态计算芯片
类脑芯片
类脑芯片架构是一款模拟人脑的神经网络模型的新型芯片编程架构,这一系统可以模拟人脑功能进行感知方式、行为方式和思维方式,使用的是脉冲神经网络(SNN)。如,清华大学天机系列芯片。

按功能分类
根据机器学习算法步骤,可分为训练和推断两个环节:
训练 (Training)
训练环节通常需要通过大量的数据输入,训练出一个复杂的深度神经网络模型。训练过程由于涉及海量的训练数据和复杂的深度神经网络结构,运算量巨大,需要庞大的计算规模。训练要求高精度、高吞吐量、强大的算力。目前市场上通常使用英伟达的GPU集群,Google的 TPU 来训练。
推断 (Inference)
推断环节是指利用训练好的模型,使用新的数据去“推断”出各种结论。这个环节的计算量相对训练环节少很多,但仍然会涉及到大量的矩阵运算。因此,对于众多应用场景来说,速度、能效、安全和硬件成本是考虑的因素。
趋势
在未来的 AI 应用当中,训练(学习)和推断在更多场景下会是交织在一起的。 推断放在边缘侧,更低延时,更安全隐私
按 AI 部署的位置

云端
云端是指在数据中心或超级计算机,利用海量的数据和庞大而复杂的深度学习算法进行模型训练,也能用作推理。
边缘侧
数据中心外的设备,如自动驾驶汽车、机器人、智能手机、物联网设备等,一般用训练好的模型进行推理。
趋势
云的边界也 逐渐向数据的源头推进,未来很可能在传统的终端设备和云端设备直接出现更多的边缘设备,把 AI 处理分布在各种网络设备(比如5G的基站)中,让数据尽量实现本地处理,这样更低延时,更安全隐私。
AI 芯片的技术挑战
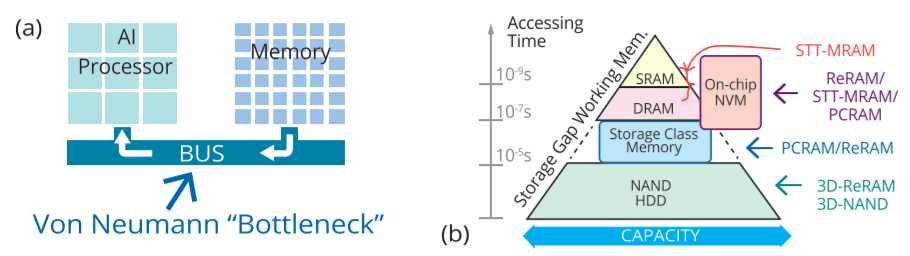
- 冯·诺依曼瓶颈
内存墙问题。
- CMOS工艺和器件瓶颈
Dennard Scaling定律已经失效,Amdahl’s Law已经达到了极限,Moore's Law也变得越来越难以遵循,而且成本也越来越高,特别是在功率和性能效益下降的情况下。
AI 芯片的优化方向
新型计算范式
目前,AI芯片主要用于DNN模型的训练和推理,计算量非常大,故需从硬件友好方面考虑对算法的改进,降低计算成本。
降低数值精度的量化技术
减少位宽,实现一个精度与硬件开销的 trade-off
压缩网络规模、修剪网络
在DNN计算中,有许多值是0或接近于0或重复的值,将这些值输入一个MAC进行乘积累加运算没有意义,浪费资源,因此需要压缩和剪枝。
二值、三值神经网络
BNN: Binary Neural Network
TNN: Ternary Neural Network
增加和利用网络稀疏性
稀疏化数据流感知
架构的设计和优化
CPU+GPU+DSA异构并行计算
存算感一体新架构
有望突破冯·诺依曼架构,存内运算、近内存计算、基于新型存储器的人工神经网络、生物神经网络,等等。
电路的设计和优化
FPGA Overlay技术
为了提高FPGA的开发效率、更好的利用FPGA的逻辑资源、方便FPGA的大规模部署和应用,需要将FPGA进行一定程度的逻辑抽象,使顶层用户不必太多关注于FPGA硬件逻辑的实现方式与细节。
模数混合电路设计MAC
软件定义芯片
可重构计算技术允许硬件架构和功能随软件变化而变化,具备处理器的灵活性和专用集成电路的高性能和低功耗,被认为是突破性的下一代集成电路技术

2023年10月24日,按照李炎原来的说法“调查一下该方向的历史发展啊,研究现状啊”进行了pre,结果被李炎说太宽泛有点水。本来就是自己没说清楚。但是,我觉得他有句话说得对,“像是在半导体大会上做报告”,这是不是说我有做企业高管领导的潜质捏?😜